



文|郝 鑫

编|刘雨琦
“99%的行业大模型都可能被替代”,百川智能联合创始人、联席总裁洪涛一语落地,震惊四座。
百模大战中,行业大模型一直都是焦点所在,原因归结起来有两点,一是和研发厂商的技术、业务结合快,二是需求明确,实际落地速度与商业化远超于通用大模型。
但这样的行业大模型通常得靠微调、精调的方式来完成,弊端也十分显而易见,训练时间长、部署成本高,还涉及企业数据隐私问题。
基于此,国内外都在找寻最优解,并形成了两种探索路径:
一种以Pinecone、Zilliz为代表的数据库公司,带火的向量数据库路线;一种是OpenAI引领起的RAG(检索增强生成)路线。
若以形象的比喻来解释,精调、向量数据库和RAG三者的区别,大模型微调好比供一个孩子从小学念到大学甚至研究生;向量数据库和RAG则更像开卷考试,不需要学习理解就能给出答案。
简而言之,向量数据库和RAG都是在不更改模型的基础上,通过一些“外挂”的手段来提升大模型应用的准确性,以此来弥补大模型自身存在的幻觉、时效性差、缺乏专业领域知识等缺陷。
尽管是两条路径选择,但向量数据库和RAG也不是完全对立,向量数据库中需要检索,RAG过程中也存在向量化阶段,只不过侧重点有所不同。
在国内,腾讯更加侧重向量数据库方向,并将其升至战略地位,做出了“大模型是计算引擎,改变的是计算方式,存储需要向量数据库”的判断。
12月,百川智能开放基于搜索增强的Baichuan2-Turbo系列API,结合RAG和向量数据库两条路线,打出了一套“大模型+超长上下文窗口+搜索增强知识库”的组合拳。
百川智能创始人、CEO王小川也给出了自己的论断:“大模型+搜索增强是大模型时代的新计算机,大模型类似于计算机的CPU,互联网实时信息与企业完整知识库共同构成了大模型时代的硬盘”。
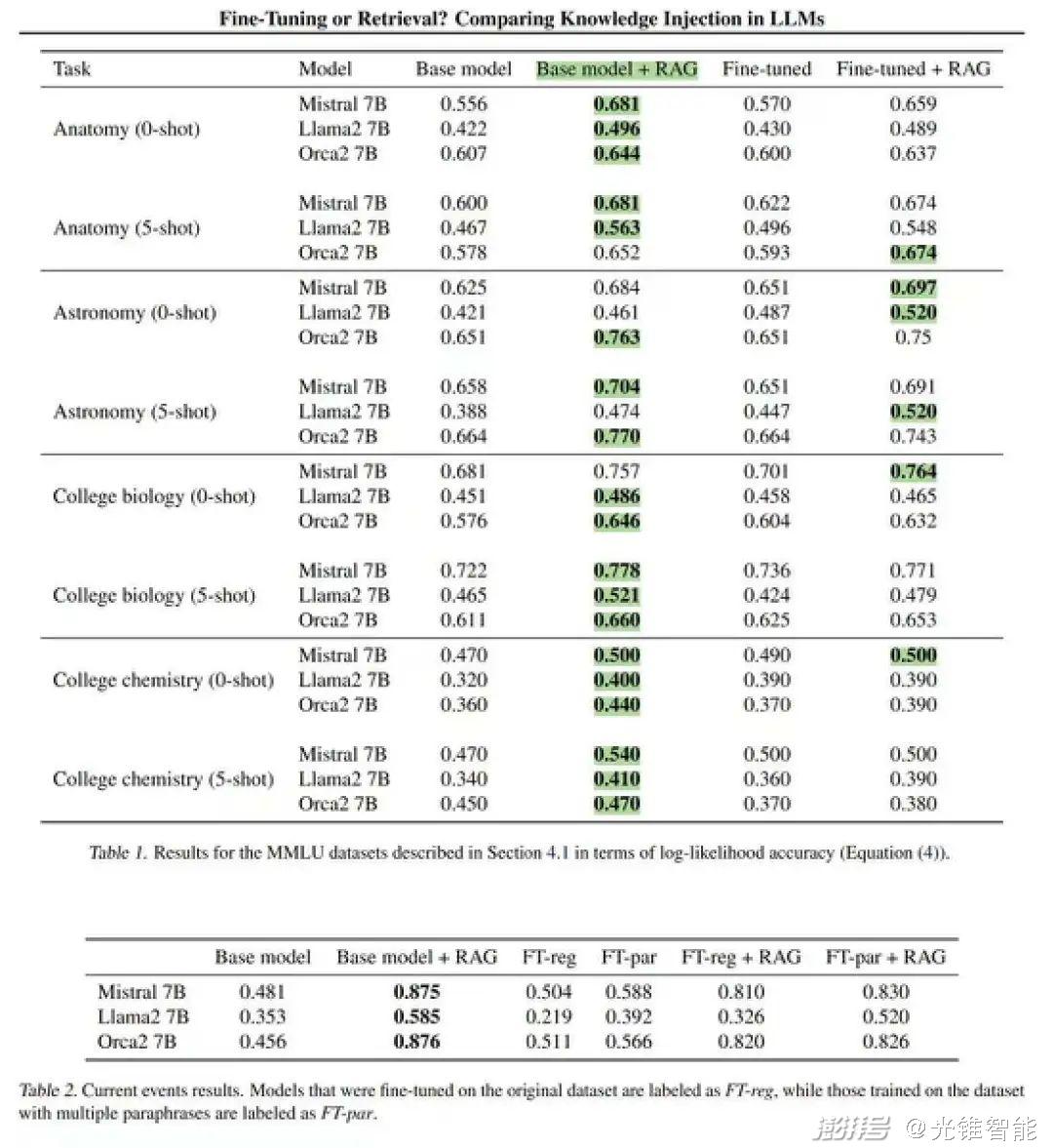
(图:实验证明RAG+大模型的效果要好于精调大模型,来自微软论文)
“从方方面面来看,搜索增强要比精调行业大模型更具性价比”,王小川道。
光锥智能在沟通会现场对话王小川,深入了解,作为较早选择RAG和向量数据库路线的企业,如何在技术上进行思考和突破?又如何在行业应用中落地?
核心观点如下:
1、搜索增强是大模型走向实用的第一步,甚至是最关键的一步。
2、大模型+搜索构成完整技术栈,实现了大模型和领域知识、全网知识的全新链接。
3、大模型+搜索增强是大模型时代的新计算机,大模型类似于CPU,互联网实时信息与企业完整知识库是硬盘。
4、避免项目化,用产品化取代项目化,用定制化的能力,实现企业的低成本定制。
5、中国大模型技术进化比想象中要快得多,追赶方向主要集中在文本领域。
以下为对话实录:
Q:在RAG提出之前,行业有哪些解决大模型缺陷的手段?
王小川:业界探索了多种解决方案,包括扩大参数规模、扩展上下文窗口长度、为大模型接入外部数据库,使用特定数据训练或微调垂直行业大模型等。这些路线各有优势,但也都存在自身的局限。
例如,持续扩大模型参数虽然能够不断提升模型智能,但是需要海量数据和算力的支撑,巨额的成本对中小企业非常不友好,而且完全依靠预训练也很难解决模型的幻觉、时效性等问题。所以,业界亟需找到一条集诸多优势于一体的路径,将大模型的智能切实转化为产业价值。
Q:百川智能提出的“搜索增强”概念与大火的RAG技术思路十分契合,如何理解“大模型+搜索”?
王小川:大模型+搜索增强是大模型时代的新计算机,大模型类似于计算机的CPU,通过预训练将知识内化在模型内部,然后根据用户的prompt生成结果;上下文窗口可以看做计算机的内存,存储了当下正在处理的文本;互联网实时信息与企业完整知识库共同构成了大模型时代的硬盘。

基于这一技术理念,百川智能以Baichuan2大模型为核心,将搜索增强技术与大模型深度融合,结合此前推出的超长上下文窗口,构建了一套大模型+搜索增强的完整技术栈,实现了大模型和领域知识、全网知识的全新链接。
Q:通过搜索增强如何来解决大模型现在存在的问题?
王小川:搜索增强能够有效解决幻觉、时效性差、专业领域知识不足等阻碍大模型应用的核心问题。一方面,搜索增强技术能有效提升模型性能,并且使大模型能“外挂硬盘”,实现互联网实时信息+企业完整知识库的“全知”。
另一方面,搜索增强技术还能让大模型精准理解用户意图,在互联网和专业/企业知识库海量的文档中找到与用户意图最相关的知识,然后将足够多的知识加载到上下文窗口,借助长窗口模型对搜索结果做进一步的总结和提炼,更充分地发挥上下文窗口能力,帮助模型生成最优结果,从而实现各技术模块之间的联动,形成一个闭环的强大能力网络。
Q:在技术路径上,“大模型+搜索”是怎样实现的?
王小川:在长上下文窗口和向量数据库的基础上,将向量数据库升级为搜索增强知识库,极大提升了大模型获取外部知识的能力,并且把搜索增强知识库和超长上下文窗口结合,让模型可以连接全部企业知识库以及全网信息,能够替代绝大部分的企业个性化微调,以此来解决99%企业知识库的定制化需求。
但在实现过程中,存在着诸多技术难题。搜索增强方面,用户的需求表达不仅口语化、多元化,并且还与上下文强相关,因此用户需求(prompt)与搜索的对齐成为了大模型获取外部知识过程中最为核心的问题。为了更精准地理解用户意图,百川智能使用自研大语言模型对用户意图理解进行微调,能够将用户连续多轮、口语化的prompt信息转换为更符合传统搜索引擎理解的关键词或语义结构。
百川智能还参考meta的CoVe(Chain-of-Verification Reduces Hallucination in Large Language Models)技术,将真实场景的用户复杂问题拆分成多个独立可并行检索的子结构问题,从而让大模型可以针对每个子问题进行定向的知识库搜索,提供更加准确和详尽的答案。同时通过自研的TSF(Think Step-Further)技术,百川智能的知识库可以推断出用户输入背后深层的问题,更精准的理解用户的意图,进而引导模型回答出更有价值的答案,为用户提供全面和满意的输出结果。
Q:大模型+搜索的测试和运行效果达到了什么样的水平?
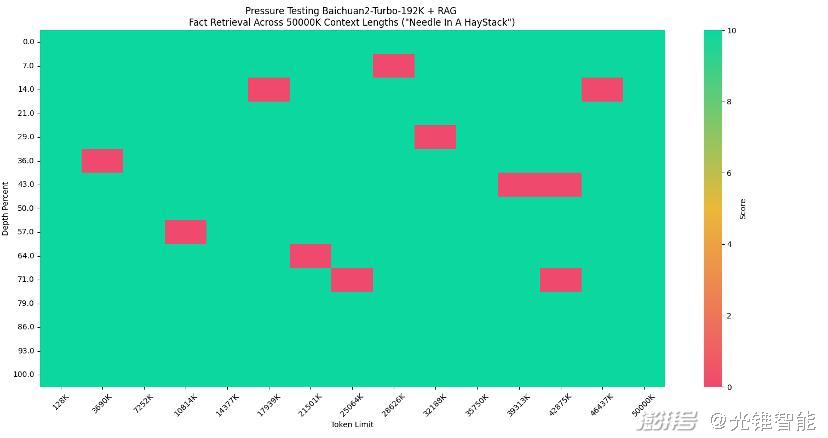
王小川:百川智能通过长窗口+搜索增强的方式,在192K长上下文窗口的基础上,将大模型能够获取的原本文本规模提升了两个数量级,达到5000万tokens。并且通过了业内公认最权威的大模型长文本准确度测试——“大海捞针”测试,对于192k token以内的请求,可以实现100%回答精度。
对于192k token以上的文档数据,百川智能结合搜索系统,将测试集上下文长度扩展到 5000w tokens。分别评测了纯向量检索和稀疏检索+向量检索的检索效果,测试结果显示,稀疏检索+向量检索的方式可以实现95%的回答精度,即使在5000万tokens的数据集中也可以做到接近全域满分,而单纯的向量检索只能实现 80%的回答精度。
Q:百川智能在推动2B落地过程中,发现了行业大模型的哪些问题?行业大模型为什么推进不下去?
王小川:行业大模型虽然是针对行业中需求而诞生的,但是现状是概念炒得很热,却没有良好的实践,面临重重困难。
行业内提出了L0、L1的概念,L0是标准模型,L1是指在上面经过垂直的领域数据进行改造。普通的改造有两个做法,一个是SFT(注:监督微调,通常在预训练的大语言模型上使用)一个是Post-train(注:模型训练后的调参、压缩、部署阶段。)行业大模型的改造跟训练模型是一个事情,虽然SFT下降了1—2个数量级的难度,技术实现上依然很难,还需要模型公司的人才介入。对企业来说,这是一个巨大的挑战和资源消耗,而一旦开始就需要GPU算力的支撑,做训练而不是推理,成本非常高。尽管投入大,但训练模型就跟“炼丹”一样,不能保证效果,还有可能会下降。再有,一旦数据或者算法更新了,企业就得再重训一次。当数据发生变化,需要引进实时数据,模型基座需要升级时,之前的训练又会彻底归零,还得重来一次。
我们不完全否定做行业大模型这件事,但是依然觉得在大部分场景下,搜索增强是可以替代行业大模型。
Q:为什么说搜索增强可以替代行业大模型?搜索增强才是走向应用的关键?
王小川:大家都在呼吁大模型要走向实用和落地,但在今天,尤其从国内来看,搜索增强才是大模型走向实用的第一步,甚至是最关键的一步,没有搜索增强的大模型在企业里没法落地。
用知识库加上搜索增强之后,直接把系统挂上去,即插即用,把“硬盘”挂上去就可以用了,并且搜索的稳定性也会好很多,避免原有做Post-train或SFT的时候可靠性、稳定性都不够,现在不管用向量检索,还是用稀疏检索都能很大程度提升。毕竟刚才提到原来知识库拖进去,训练完了,只要发现数据更新就得重新训。现在用“硬盘”挂接方式即插即用,避免了原来模型升级的时候,模型跟你的体制是分离的,模型升级模型的,硬盘升级硬盘的。比现有训练行业模型,用搜索增强+大模型的方式会带来很大优势。
Q:搜索增强能撬动哪些行业?将带来哪些新的改变?
王小川:大模型+搜索增强解决方案解决掉幻觉和时效性问题后,有效提升了大模型的可用性,拓展了大模型能够覆盖的领域,例如金融、政务、司法、教育等行业的智能客服、知识问答、合规风控、营销顾问等场景。
一个是大量文本数据的,有文本数据的,需要把文字的know how去做处理的,第二个是跟客户打交道的,他需要跟客户沟通,比如客服的场景,或者回答客户问题的,这两个场景比较集中,发挥大模型的两个优势,有无限供给的能力。

Q:百川智能商业化进展到了什么阶段?如何思考定制化和产品化的关系?
王小川:在商业化线索沟通中,百川智能发现,前期很多客户想了解大模型,很多人来问大模型到底是什么,能干什么。而最近两个月,客户的问题越来越具体,已经有一些场景感受到能用大模型了。但是解决的时候比较痛苦,最基础的是微调,狠一点的 SFT、Post-Training 都会提,但这些其实都很重。我们现在做这件事的目的就是告诉客户,我能快速地落地到你的实际应用去,所以现在无论是私有化场景的,还是API场景的,很多客户都在沟通,我们这次发布的产品就是解决他们这个问题。
所谓定制化,customize,更准确地说是个性化,客户天生有个性化的需求。百川希望避免的,是项目化,用产品化取代项目化,是指产品具有定制化的能力,能够实现企业的低成本定制。
核心还是成本,客户成本高,项目利润低。相对能盈利的2B公司,卖的大多是产品,而大多数定制化是项目。搜索增强的完整技术栈,目的就是让API外挂企业知识库实现定制化,是一款产品,可配置、可调整。我们也希望在为私有化客户做定制化的时候,用产品组合的方式来做,而不是用全都重新开发一遍的方式做。
Q:百川智能作为大模型浪潮的亲历者,回顾这一年,经历了哪些阶段?
王小川:中国现在来讲总的分成三个阶段。
第一个阶段是恐慌期,OpenAI发布了ChatGPT后,中国公司还没有,数据飞轮美国先跑起来,那时大家都在讨论是不是AGI要来了;
第二个阶段是投入期,比如我开始做百川智能,大家都开始动起来了,不断地有人加入进来,所有的关注点都在大模型上;
第三个阶段是高速迭代期,无论是资本、学术还是业界,每天都能看到新的进展,我们的技术人员每天都在跟进最新的东西,让自己不断迭代和改进,行业中的发展速度其实超出外界媒体和资本圈的看法,目前还是在快速迭代。
Q:如果从技术视角看,中国的大模型更新迭代有哪些特点?
王小川:首先,中国大模型技术进化比想象中要快得多。刚开始大家都觉得美国的优势特别明显,我们追不上。但后来包括百川智能在内的各家大模型出来以后,才发现在有些场景中比GPT-3.5甚至4还要好一些,这是已经发生的事实。比如百川智能,6月份发第一款模型,7月份发第二款,8月份发500亿参数,一直在往前进行中,在开源领域还是美国的替代产品。
第二个特点是,国内追赶的方向还是集中在文本领域。文本代表着智力化水平,我们认为在追赶智力水平上,把文本放在第一位的公司,是在朝着长远方向走。GPT到GPT-4也才开始有了GPT-4V多模态,所以那些考虑音频、图像、视频的公司,这个时候反而不是在一个方向竞争。
本文地址:http://syank.xrbh.cn/quote/7639.html 迅博思语资讯 http://syank.xrbh.cn/ , 查看更多